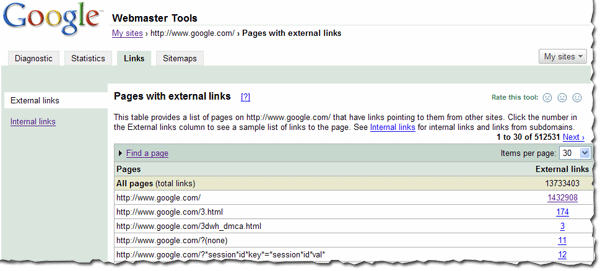
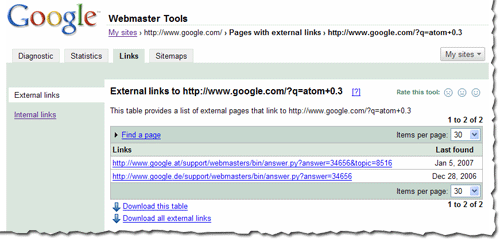
Search engine robots, including our very own Googlebot, are incredibly polite. They work hard to respect your every wish regarding what pages they should and should not crawl. How can they tell the difference? You have to tell them, and you have to speak their language, which is an industry standard called the Robots Exclusion Protocol.
Dan Crow has written about this on the Google Blog recently, including an introduction to setting up your own rules for robots and a description of some of the more advanced options. His first two posts in the series are:
Controlling how search engines access and index your website
The Robots Exclusion Protocol
Stay tuned for the next installment.
While we're on the topic, I'd also like to point you to the robots section of our help center and our earlier posts on this topic:
Debugging Blocked URLs
All About Googlebot
Using a robots.txt File
Update: For more information, please see our robots.txt documentation.
Dan Crow has written about this on the Google Blog recently, including an introduction to setting up your own rules for robots and a description of some of the more advanced options. His first two posts in the series are:
Controlling how search engines access and index your website
The Robots Exclusion Protocol
Stay tuned for the next installment.
While we're on the topic, I'd also like to point you to the robots section of our help center and our earlier posts on this topic:
Debugging Blocked URLs
All About Googlebot
Using a robots.txt File
Update: For more information, please see our robots.txt documentation.